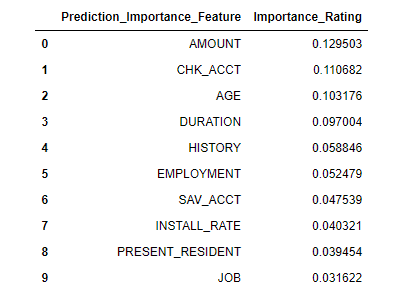
Top 10 Most Important Features
Definition: A random forest is a meta estimator that fits numerous decision tree classifiers on various
sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting.
(scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html)
The Random Forest is ensemble method from SkLearn library, it shows how appropriated columns values to feature
importance ratios. So, each individual test has variable of conditions is based on a ratio importance that help
determine the predicted result.
It is the based logic that outlines the mathematical process in the final decision and/or prediction. The
CliffsNotes of Machine Learning’s little black box.
This Random Forest read in 31 Columns from the Credit DataOriginal.csv to classify. The RandomForestClassifier
from SkLearn fits the default.data (less the DEFAULT column) with default.target ( just the DEFAULT column).
In order to analyze the list, a Data Frame was created displaying Feature Importance and the corresponding
rating.
Then, the iloc of the top ten was utilized while sorting by descending order.
This returned the Top Ten Importance Features that were used to revise specific columns in a new data frame. The
10 columns along with the DEFAULT column became the Credit_Data_Revised.cvs used in the Neural Network
Model.
Prediction Importance Feature and Acending Ratings
Automatically, the RandomForestClassifier calculates the feature importance rating.
The rating is the weighted value of each Feature (column) in the decision process.
By sorting the feature importance in descending order, the highest feature rating lists 1–30.